Efficient Implementation of Experimental Run Order
Once designs have been created, it is often important to optimize the run order to efficiently reach equilibrium and allow for the maximum number of runs to be implemented within a constrained budget or time period. While statisticians generally recommend using a randomized order for the experimental runs, it can sometimes mean the difference of a small randomized experiment versus a larger non-randomized experiment.
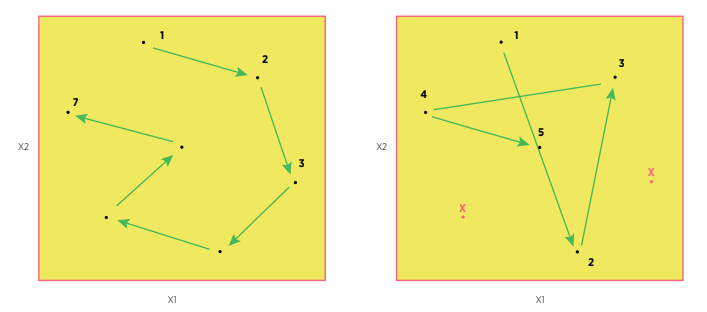
Comparison of the number of runs possible with an optimized run order (left) versus an inefficient randomized run order (right)
In this section we describe how to generate an efficient run order for a design created using the Uniform Space Filling or Non-Uniform Space Filling design options.
Once we created a design (USF or NUSF), it appears on the left panel in the Created Designs table. Click on the design that we want to order (it is highlighted in blue as shown below). Then click on the button below named Order Design, to order the design points in an efficient run order that sequences the runs to favor having nearby points adjacent to each other in the run order.
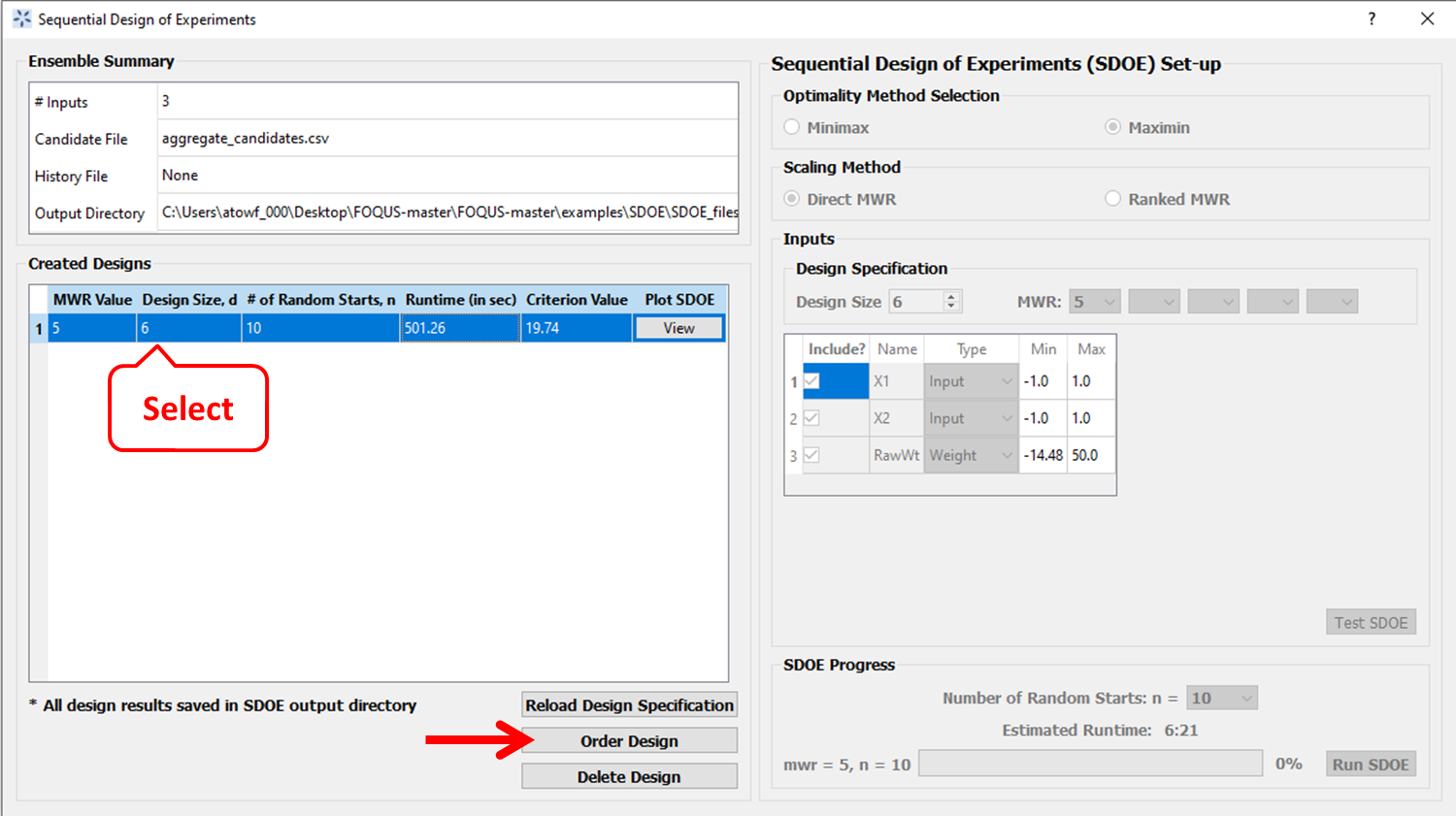
How to create an ordered design
A pop up window confirms the location of the newly ordered file (see below). Click ‘Yes’ to continue.
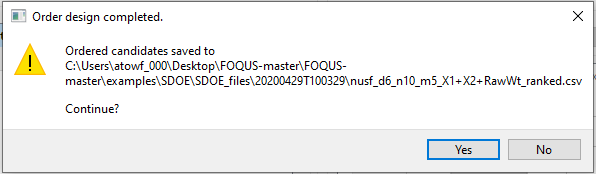
Message window for new design created
Both design files (located in the designated folder) are saved in the csv format, which can be opened with your preferred application (e.g. Microsoft Excel). You can produce a scatterplot of the ordered design file either using FOQUS or any other external application.
The ordering scheme provides a method for the user to design the experimental run order that follows the minimal path distance to traverse from one design point to another, i.e., minimal changes the the experimental processes. This standardizes the range of each input factor t to be between 0 and 1, and then minimizes the sum of the Euclidean distances between all of the points. Often this would be a preferred operational implementation to increase the efficiency of the experiment, by reducing the time for the process to reach equilibrium. The implementation provided uses the TSP (travelling sales person) algorithm as implemented in the ‘python-tsp’ library package for ordering/ranking the design points.
An alternative to this approach is a simple sequential ordering (ascending or descending) of the most expensive input factor. This is easily implemented by the user, and can be efficient for the running of the experiment, but should be used cautiously because the run order might confound other changes in the system during the implementation of the experiment.