Sequential Design of Experiments (SDOE)¶
A sequential design of experiments strategy allows for adaptive learning based on incoming results as the experiment is being run. The SDoE module in FOQUS allows the experimenter to flexibly incorporate this strategy into their designed experimental planning to allow for maximal relevant information to be collected. Statistical design of experiments is an important strategy to improve the amount of information that can be gleaned from the overall experiment. It leverages principles of putting experimental runs where they are of maximum value, the interdependence of the runs to estimate model parameters, and robustness to the variability of results that can be obtained when the same experimental conditions are repeated. There are two major categories of designed experiments: those for which a physical experiment is being run, and designs for a computer experiment where the output from a theoretical model is explored. While the methods available were initially focused on experiments for physical experiments, opportunities also exist for accelerated learning through strategic selection and updating of experimental runs for computer experiments.
The overall process for Sequential Design of Experiments (SDoE) is detailed below:
- Identify one or more criteria over which to optimize. Common choices are (a) refining the region of interest, (b) improving the precision (or reducing the uncertainty) in the estimation of model parameters, (c) improving the precision of prediction for new observations in the design region, (d) quantifying the discrepancy between the model and data, or (e) optimizing the value of responses of interest. If more than one criterion is going to be used, then identify how they will be combined into a utility function.
- Develop a working model of the process that can be used to calculate the criteria values based on currently available knowledge and data.
- Define the inputs that will be manipulated during the experiment, and the ranges of interest for these factors.
- Identify candidate input factor locations that are being considered for new experiments. This can be a grid of input combinations or continuous regions in the design space. If there are combinations of the factors that will not yield results or that are not of interest, these regions of the design space should be excluded from consideration.
- Develop a working model of the process that is able to receive new data and incorporate them to update the calculated criteria values.
- Develop a plan for the size of the sequential design batches, based on the time required to set-up and run the experiments as well as the computational time required to process new data and update the working model.
- Identify the initial batch of experiments to be run at the beginning of the experiments based on the model developed in step 2 and conditional on any already available data. This involves examining the utility of new data at each candidate location, and comparing which locations have the highest anticipated utility.
- Run the first batch of experimental runs, update the model developed in step 5 with the new results. Based on the updated model, generate the next batch of experimental runs.
- For the duration of the experiment, repeat steps 7 and 8 for subsequent batches based on the updated model after incorporating the newly obtained data.
The first version of the SDoE module has functionality that can produce flexible space-filling designs to be created. Later versions will allow for additional design criteria to be utilized, but the first version already had considerable flexibility to construct helpful design based on several different strategies. Key features of the approach that we use in this module are: a) designs will be constructed by selecting from a user-provided candidate set of input combinations, and b) historical data, which has already been collected can be integrated into the design construction to ensure that new data are collected with a view to disperse from where data are already available.
We begin with some basic terminology that will help provide structure to the process and instructions below.
- Input factors – these are the controllable experimental settings that are manipulated during the experiment. It is important to carefully define the ranges of interest for the inputs (eg. Temperature in [200°C,400°C]) as well as any logistical or operational constraints on these input factors (eg. Flue Gas Rate < 1000 kg/hr when Temperature > 350°C)
- Input combinations (or design runs) – these are the choices of settings for each of the input factors for a particular run of the experiment. It is assumed that the implementers of the experiment are able to set the input factors to the desired operating conditions to match the prescribed choice of settings.
- Input space (or design space) – the region of interest for the input factors in which the experiment will be run. This is typically constructed by combining the individual input factor ranges, and then adapting the region to take into account any constraints. Any suggested runs of the experiment will be located in this region.
- Responses (or outputs) – these are the measured results obtained from each experimental run. These are most desirably quantitative summaries of a characteristic of interest from running the process at the prescribed set of operating conditions (eg. CO2 capture efficiency is a typical response of interest for CCSI).
- Design criterion / Utility function – this is a mathematical expression of the goal (or goals) of the experiment that is used to guide the selection of new input combinations, based on the prior information before the start of the experiment and during the running of the experiment. The design criterion can be based on a single goal or multiple competing goals, and can be either static throughout the experiment or evolve as goals change in importance over the course of the experiment. Common choices of goals for the experiment are:
- exploring the region of interest,
- improving the precision (or reducing the uncertainty) in the estimation of model parameters,
- improving the precision of prediction for new observations in the design region,
- quantifying the discrepancy between the model and data, or
- optimizing the value of responses of interest.
An optimal design of experiment strategy uses the design criterion to evaluate potential choices of input combinations to maximize the improvement in the criterion over the available candidates. If the optimal design strategy is sequential, then the goal is to use early results from the beginning of the experiment to guide the choice of new input combinations based on what has been learned about the responses.
Why Space-Filling Designs?¶
Space-filling designs are a design of experiments strategy that is well suited to both physical experiments with an accompanying model to describe the process and to computer experiments. The idea behind a space-filling design is that the design points are spread throughout the input space of interest. If the goal is to predict values of the response for a new set of input combinations within the ranges of the inputs, then having data spread throughout the space means that there should be an observed data point relatively close to where the new prediction is sought.
In addition, if there is a model for the process, then having data spread throughout the input space means that the consistency of the model to the observed data can be evaluated at multiple locations to look for possible discrepancies and to quantify the magnitude of those differences throughout the input space.
Hence, for a variety of criteria, a space-filling design can serve as good choice for exploration and for understanding the relationship between the inputs and the response without making a large number of assumptions about the nature of that relationship. As we will see in subsequent examples, the sequential approach allows for great flexibility to leverage what has been learned in early stages to influence the later choices of designs. In addition, the candidate-based approach that is supported in this module has the advantage that it can make the space-filling approach easier to adapt to design space constraints and specialized design objectives that may evolve through the stages of the sequential design.
Using the SDoE Module - The Basics¶
In this section, we descibe the basic steps in for creating a design with this module. When you first click on the SDOE button from the main FOQUS homepage, a first window appears. To create a design, the progression of steps takes you through the Ensemble Selection box (top left), then a transition triggered by the Confirm button to the Ensemble Aggregation box, and finally there are optional changes that can be made in the box at the bottom of the window. The final step in this window is to click on Analyze.
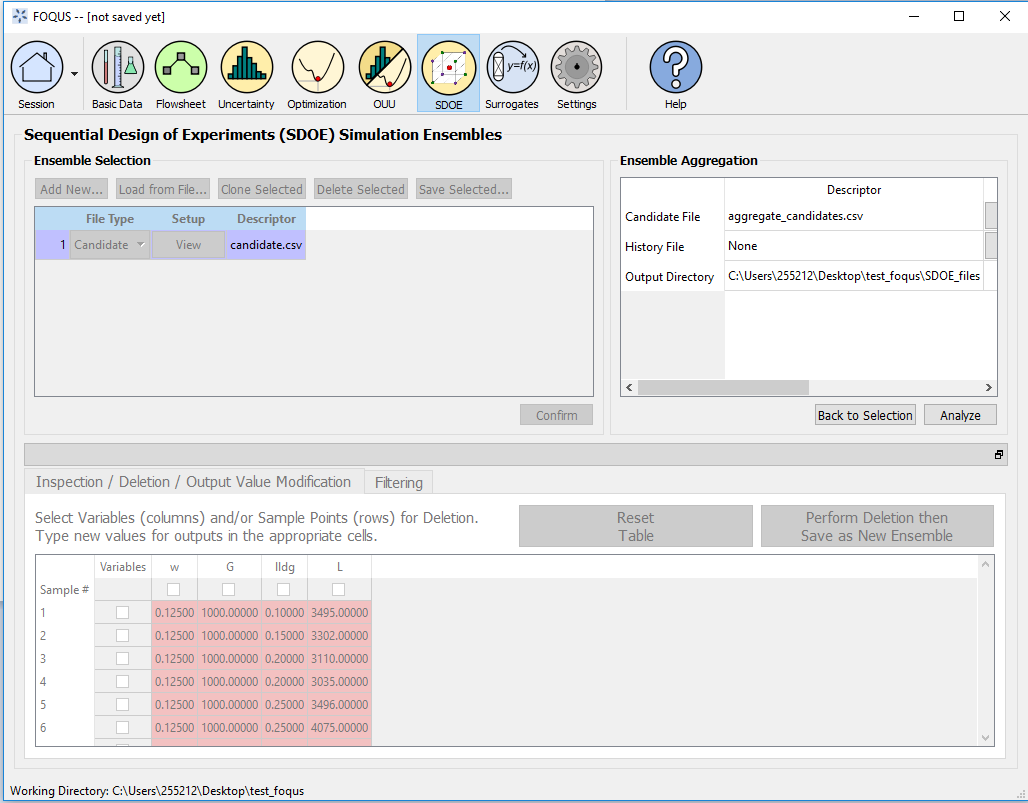
SDOE Home Screen
We now consider some details for each of these steps:
- In the Ensemble Selection box, click on the Load from File.. button to select the file(s) for the construction of the design. Several files can be selected and added to the box listing the chosen files.
2. For each of the files selected using the pull-down menu, identify them as either a Candidate file or a History file. Candidate .csv files are comprised of possible input combinations from which the design can be constructed. The columns of the file should contain the different input factors that define the dimensions of the input space. The rows of the file each identify one combination of input values that could be selected as a run in the final design. Typically, a good candidate file will have many different candidate runs listed, and they should fill the available ranges of the inputs to be considered. Leaving gaps or holes in the input space is possible, but generally should correspond to a region where it is not possible (or desirable) to collect data. History .csv files should have the same number of columns for the input space as the candidate file, and represent data that have already been collected. The algorithm for creating the design aims to place points in different locations from where data have already been obtained, while filling the input space around those locations.
- Click on the View button to open the Preview Inputs pop-up widow, to see the list of columns contained in each file. The left hand side displays the first few rows of input combinations from the file. Select the columns that you wish to see graphically in the right hand box , and then click on Plot SDOE to see a scatterplot matrix of the data.
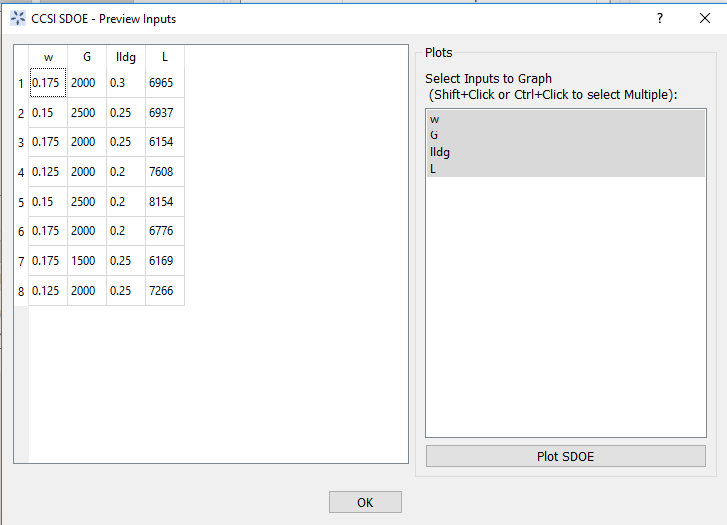
SDOE preview of inputs
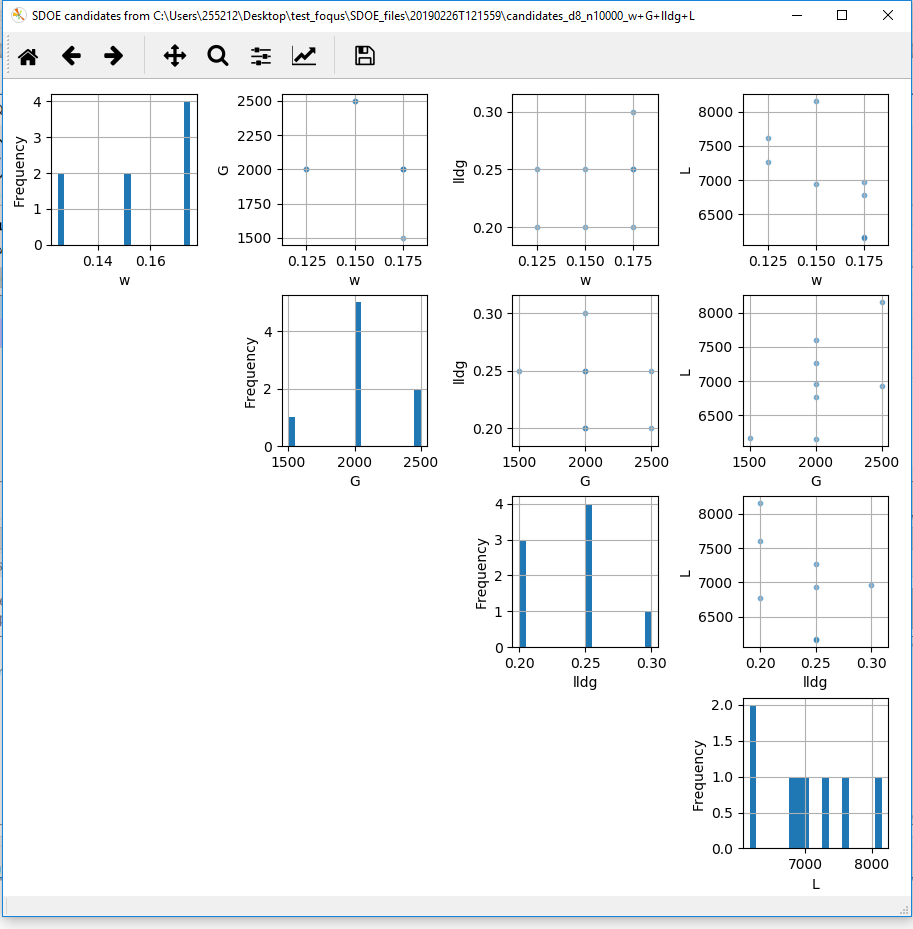
SDOE plot of inputs
The plot shows histograms of each of the inputs on the diagonals to provide a view of the distribution of values as well as the range of each input. The off-diagonals show pairwise scatterplots of each pair of inputs. This should provide the experimenter with the ability to assess if the ranges specified and any constraints for the inputs have been appropriately captured for the specified candidate set. In addition, repeating this process for any historical data will provide verification that the already observed data have been suitably characterized.
- Once the data have been verified for both the Candidate and History files, click on the Confirm button to make the Ensemble Aggregation window active.
- If more than one Candidate file was specified, then the aggregate_candidates.csv file that was created will have combined these files into a single file. Similarly if more than one Histoy file was specified, then the aggregate_history.csv file has been created with all runs from these files. If only a single file was selected for either the Candidate and History files, then their aggregated matching files will be the same as the original.
- Once the data have been verified as the desired set to be used for the design construction, then click on the Analyze button at the bottom right corner of the Ensemble Aggregation window. This opens the second SDOE window, which allows for specific design choices to be made.
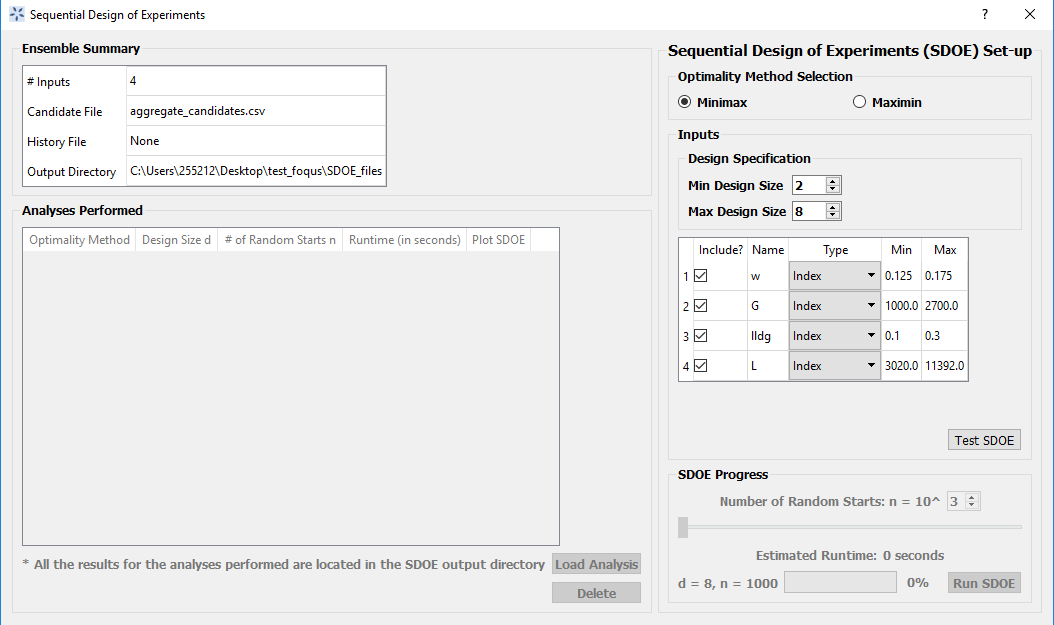
SDOE second window
- The first choice to be made for the design is whether to optimize using minimax or maximin. The first choice, minimax, looks to choose design points that minimize the maximum distance that any point in the input space (as characterized by the candidate set and historical data, if it is available) is away from a design point. Hence, the idea here is that if we want to use data to help predict new outcomes throughout the input space, then we never want to be too far away from an observed location. The second choice, maximin looks to choose a design where the design points are as far away from each other as possible. In this case, the design criterion is looking to maximize how close any two points are away from their nearest neighbor. In practice the two design criterion often give similar designs, with the maximin criterion tending to push the chosen design points closer to the edges of the specified regions.
Hint: If there is uncertainty about some of the edge points in the candidate set being viable options, then minimax would be preferred. If the goal is to place points throughout the input space with them going right to the edges, than maximin would be preferred. Note, that creating the designs is relatively easy, so it may be helpful to try both approaches to examine them and then choose which is preferred.
8. The next choice to be made falls under Design Specification, when the experimenter can select the sizes of designs to be created. The Min Design Size specifies the smallest design size to be created. Not that the default value is set at 2, which would lead to choosing the best two design runs from the candidate set to fill the space (after taking into account any historical data that have already been gathered). The Max Design Size specifies the largest design size to be created. The default value is set at 8, which means that if this combination were used, designs would be created of size 2, 3, 4, 5, 6, 7 and 8. Hence, it may be prudent to select a relatively small range of values to expedite the creation of the designs, as each of these choices triggers a separate optimization search.
- Next, there are options for the columns of the candidate set to be used for the construction of the design. Under Include? in the box on the right hand side, the experimenter has the option of whether particular columns should be included in the space-filling design search. Unclick a box, if a particular column should not be included in the search.
Next select the Type for each column. Typically most of the columns will be designated as Inputs, which means that they will be used to find the best design. In addition, we recommend including one Index column which contains a unique identifier for each run of the candidate set. This makes tracking which runs are included in the constructed designs easier. If no Index column is specified, a warning appears later in the process, but this column is not strictly required.
Finally, the Min and Max columns in the box allow the range of values for each input column to be specified. The default is to extract the smallest and largest values from the candidate and history data files, and use these. This approach generally works well, as it scales the inputs to be in a uniform hypercube for comparing distances between the design points.
Hint: the default values for Min and Max can generally be left at their defaults unless: (1) the range of some inputs represent very different amounts of change in the process. For example, if temperature is held nearly constant, while a flow rate changes substantially, then it may be desirable to extend the range of the temperature beyond its nominal values to make the amount of change in temperature more commensurate with the amount of change in the flow rate. (2) if changes are made in the candidate or history data files. For example, if one set of designs are created from one candidate set, and then another set of designs are created from a different candidate set. These designs and the achieved criterion value will not be comparable unless the range of each input has been fixed at matching values.
- Once the design choices have been made, click on the TestSDOE button. This generates a small number of iterations of the search algorithm to calibrate the timing for constructing and evaluating the designs. The time taken to generate a design is a function of the size of the candidate set, the size of the design, as well as the dimension of the input space. The slider below TestSDOE now indicates an estimate of the time to construct the designs across the range of the Min Design Size and Max Design Size specified. The smallest Number of Random Starts is 10^3 = 1000 is generally too small to produce a good design, but this will run very quickly. Powers of 10 can be chosen with an Estimated Runtime provided below the slider.
Hint: The choice of Number of Random Starts involves a trade-off between the quality of the design generated and the time to generate the design. The larger the chosen number of random starts, the better the design is likely to be. However, there are diminishing gains for increasingly large numbers of random starts. If running the actual experiment is expensive, it is generally recommended to choose as large a number of random starts as possible for the available time frame, to maximize the chance of an ideal design being found.
- Once the slider has been set to the desired Number of Random Starts, click on the Run SDOE button, and initate the construction of the designs. The progress bar indicates how design construction is progressing through the chosen range of designs between the Min Design Size and Max Design Size specified.
Example 1: 8-run 2-D design¶
For this first example, the goal is to construct a simple space-filling design with 8 runs in a 2-dimensional space using the example files provided with FOQUS.
- From the FOQUS main screen, click the SDOE button. On the top left side, select Load from File, and select the candidate.csv file from examples folder. This identifies the possible input combinations from which the design will be constructed. The more possible candidates that can be provided to the search algorithm used to construct the design, the better the design might be for the specified criterion. Home Screen.
Home Screen